Simple SQL
Here’s how to use simple SQL.
Concept:
A simple SQL is used to query data in a data file, which is represented directly using the table name【file name.extension】and which can be treated as an ordinary table sequence. It is so called because the syntax is similar to that of database queries.
The file types simple SQL supports include txt, csv, xlsx, xls and btx (a bin file). Each involved data file is supposed to have headers. Both the relative path, which is relative to the esProc main directory, and the absolute path can be used in a simple SQL query.
Similar to familiar SQL statements, simple SQl can be used in db.query(sql) and $(db)sql. While the ordinary SQL queries data from the database through a specified to-be-connected data source db, the simple SQL queries data from a file system without specifying data source name. It just leaves data source parameter db null with syntax connect().query(sql)/$()sql.
Syntax of simple SQL:
|
with T as (x) |
Define a table for data file using an esProc script; the query over the file x returns a table sequence or a cursor |
|
select x F,… |
Select data from a table where x is a field or an expression, and F is its alias. |
|
_file |
The field is file name when data is imported from a file; it won’t be defined when data comes from other types of sources |
|
_ext |
The filename extension. |
|
_size |
The size of a file. |
|
_date |
The last modified date of a file. |
|
* |
The symbol * represents fields in the file only; it does not contain file attributes. |
|
.from T T’ |
Use a defined table T; T’ is the alias of this table and can be omitted. |
|
from fn T |
Use file fn, whose format can be txt, csv, xls, xlsx and btx (a bin file), directly as table T; the file is opened as a cursor, and by default considered to have headers; use a relative path, which is relative to esProc main directory, or an absolute path to access file fn. Support using wild character in the file name, where * matches zero or multiple characters and ? matches a single character; T can correspond to multiple files and be treated as the union of multiple same-structure data files; do not support accessing the subdirectory. |
|
from {x} |
x is an expression that can be executed within the current cellset; it should be an esProc expression that returns a table sequence or a cursor. |
|
from v |
v is name of a variable across the current network. |
|
as |
Can be used before a table alias. |
|
where |
The conditional filtering. |
|
join, left join and full join |
Associative operations that handle all data in the memory when join operator is present; the corresponding function is xjoin(). |
|
group by |
Grouping operation with groups() function, whose result set is supposed to be able to fit into the memory. |
|
group by n |
Perform grouping by the nth expression in the select statement; n should be a constant. |
|
having |
Grouping and filtering. |
|
order by |
Sorting operations in, by default, ascending order. |
|
order by n |
Perform sorting by the nth expression in the select statement; n should be a constant. |
|
distinct |
Synonym of SQL DISTINCT clause; support only a single table. |
|
and, or, not, in, is null and case when else end |
Used in SQL style; in only supports sets of constants and doesn’t support subqueries.
|
|
between |
A data range sandwiched by two values, such as value f1 that falls between 1 and 3, which can be written as f1 >= 1 && f1 <= 3 |
|
like |
Fuzzy query, which supports the following wildcard characters: % Match multiple characters; _ Match a single character; The operator does not support subqueries. |
|
into fn |
Write the result set to file fn, whose format, which can be txt, csv and btx, is determined by its extension; Check whether the result set and the target file have same structure if the latter already exists; then perform appending if they have same structure, otherwise error will be reported; Use a relative path, which is relative to esProc main directory, or an absolute path to access the file. |
|
into ${x}.ext |
Can use a macro string in the file name and concatenate the result of calculating the macro expression into the file name. |
|
?, ?i |
Parameters in a simple SQL statement; i represents the ith parameter. |
|
aggregate functions |
sum, count, max, min and avg, distinct and count(distinct). |
|
set operations |
union, union all, intersect and minus. |
|
subquery |
All subqueries are supposed to be able to be wholly executed in memory except for the from statement; support non-parameter subqueries. |
|
compute functions |
Defined under sqltranslate() function (without database name and have corresponding SQL expressions); do not support window functions. |
|
top n |
Get first n records. |
|
limit n offset m |
Skip m records to get n records. |
|
other functions |
esProc functions conforming to syntax. |
|
String functions: |
|
|
LOWER(str) |
Convert to lower case. |
|
UPPER(str) |
Convert to upper case. |
|
LTRIM(str) |
Delete whitespaces on the leftmost side. |
|
RTRIM(str) |
Delete whitespaces on the rightmost side. |
|
TRIM(str) |
Delete whitespaces on both sides. |
|
SUBSTR(str,start,len) |
Return a substring. |
|
LEN(str) |
Return length of a string. |
|
INDEXOF(sub,str[,start]) |
Return position of a substring. |
|
LEFT(str,len) |
Return substring of the specified length beginning from the leftmost of a string. |
|
RIGHT(str,len) |
Return substring of the specified length beginning from the rightmost of a string. |
|
CONCAT(str1,str2) |
Concatenate two strings. |
|
CONCAT(s1,s2,…) |
Concatenate multiple strings. |
|
REPLACE(str,sub,rplc) |
Replace a substring by another string. |
|
Numeric functions: |
|
|
ABS(x) |
Return absolute value. |
|
ACOS(x) |
Return arc cosine. |
|
ASIN(x) |
Return arc sine. |
|
ATAN(x) |
Return arc tangent. |
|
ATAN2(x,y) |
Return arc tangent. |
|
CEIL(x) |
Return the smallest integer not less than x. |
|
COS(x) |
Return cosine value. |
|
EXP(x) |
Return the base of e to the power of x. |
|
FLOOR(x) |
Return the biggest integer that not greater than x. |
|
LN(x) |
Return the natural logarithm. |
|
LOG10(x) |
Return the logarithm with base 10. |
|
MOD(x,m) |
Return the remainder of x divided by m. |
|
POWER(x,y) |
Return the value of x raised to the power of y. |
|
ROUND(x,n) |
Return x rounded to n digits from the decimal point. |
|
SIGN(x) |
Return the sign for x. |
|
SIN(x) |
Return the sine value. |
|
SQRT(x) |
Return the square root of x. |
|
TAN(x) |
Return the tangent value. |
|
TRUNC(x,n) |
Return x truncated to n decimal places. |
|
RAND(seed) |
Return a random number. |
|
Date&Time functions: |
|
|
YEAR(d) |
Return the year. |
|
MONTH(d) |
Return the month. |
|
DAY(d) |
Return the day of the month. |
|
HOUR(d) |
Return the hour. |
|
MINUTE(d) |
Return the minute. |
|
SECOND(d) |
Return the second. |
|
QUARTER(d) |
Return the quarter. |
|
DATE(d) |
Return the date. |
|
TIME(d) |
Return the time. |
|
TODAY() |
Return the date. |
|
NOW() |
Return the current time. |
|
ADDYEARS(d,n) |
Add years. |
|
ADDMONTHS(d, n) |
Add months. |
|
ADDDAYS(d, n) |
Add days. |
|
ADDHOURS(d, n) |
Add hours. |
|
ADDMINUTES(d, n) |
Add minutes. |
|
ADDSECONDS(d, n) |
Add seconds. |
|
DAYOFYEAR(d) |
Return the day of year. |
|
DAYOFWEEK(d) |
Return the day of the week; 1 represents Sunday. |
|
WEEKOFYEAR(d) |
Return the calendar week of the date. |
|
ITX(s) |
Generate a time interval constant according to the time component; s represents second. |
|
ITX (null,d) |
Generate a time interval constant according to the time component; d represents day; value of the first parameter is always null. |
|
ITX(null,d,m) |
Generate a time interval constant according to the time component; d represents day and m represents month; value of the first parameter is always null. |
|
ADDX(t,k) |
Perform addition operation between two dates. k can be a time interval constant returned by ITX(). When t is a date/datetime value and k is a numeric value, k represents the day. Perform the addition operation when both t or k is of any of the other data type. |
|
SUBX(t1,t2) |
Perform subtraction operation between two dates. When t1 is a date/datetime value and t2 is a numeric value, t2 represents the day. Perform the subtraction operation when both t1 or t2 is of any of the other data type. |
|
CMPX(it1,it2) |
Perform comparison between two dates. it1 and it2 can be a date, time, datetime, time interval constant, or numerica value. |
|
Conversion functions: |
|
|
ASCII(str) |
Return ASCII code of the left-most character in a string. |
|
CHR(n) |
Convert an integer to characters. |
|
INT(x) |
Convert a string or a number to integer. |
|
DECIMAL(x,len,scale) |
Convert a string or a number to number. |
|
TIMESTAMP(str) |
Convert format string yyyy-MM-dd HH:mm:ss to datetime type. |
|
NUMTOCHAR(d) |
Convert a number to string. |
|
DATETOCHAR(date) |
Convert a date to a string whose format is yyyy-MM-dd HH:mm:ss. |
|
DATE(x) |
Convert format string yyyy-MM-dd to date type. |
|
TIME(str) |
Convert format string HH:mm:ss to time type. |
|
CAST(x,y) |
Convert data x to data of type y. |
|
Others: |
|
|
NULLIF(x1,x2) |
Return null if x1is equal to x2, otherwise return x1. |
|
COALESCE(x1,…) |
Return the first non-null parameter. |
|
CASE(when1,then1,…[,else]) |
If when=true, return the corresponding then, otherwise return else. |
Note:
In a simple SQL statement, a string used for field name, file path, file name or alias should be enclosed by double quotation marks when it contains one or more special identifiers or has a non-underline or non-letter beginning character, otherwise error will be reported. When using quotation marks, make sure they are escaped if needed.
Example:
When used in db.query(sql):
|
|
A |
|
|
1 |
=connect() |
|
|
2 |
=A1.query("select * from Persons.txt") |
|
|
3 |
=A1.query("select * from D:/Orders.txt") |
|
|
4 |
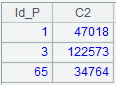
=A1.query("select Id_P, sum(OrderNo) from Orders.csv group by 1 ") |
Group by Id_P field.
|
|
5 |
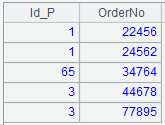
=A1.query("select Id_P, OrderNo from Orders.csv order by 2 ") |
Sort by OrderNo field in default ascending order.
|
|
6 |
=A1.query("select * into p1.txt from Persons.csv ") |
Write the query result set to file p1.txt. |
|
7 |
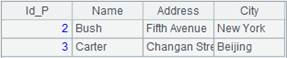
=A1.query("select * from Persons.csv where Id_P=? or Id_P>? ",2,2) |
Retrieve records where Id_P is equal to or greater than 2.
|
|
8 |
=A1.query("select * from Persons.csv where Id_P=?1 or Id_P>?2 ",2,2) |
Retrieve records where Id_P is equal to or greater than 2 and get same result as above; ?i represents the ith parameter.
|
|
9 |
=A1.query("with persons as (file(\"D:/Persons.btx\").import@b()) select * from persons ") |
Perform a query over Persons.btx, name the result set persons, and perform a second query over persons; this can optimize SQL huge data processing.
|
|
10 |
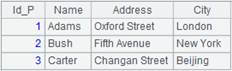
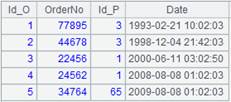
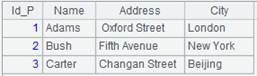
=A1.query("select * from Persons.txt P join Orders.txt O on P.Id_P = O.Id_P ") |
Perform a query through a join.
|
|
11 |
=A1.query("select distinct _file,_ext,_size,_date from cities.txt") |
Perform a distinct query, which gets the specified file’s name, extension, size, and last modified datetime.
|
|
12 |
=A1.query(“"select CASE id_P when 1 then 'one' when 2 then 'tow' else 'other' end from p1.txt") |
case when statement is used here. |
|
13 |
=A1.query("select * from Persons.btx where city like 'N%' ") |
Use like syntax to find from file Persons.btx the record where the first character of city field is N.
|
|
14 |
=A1.query("select * from Persons.btx where Name like '_a_t%' ") |
Use like syntax to find from file Persons.btx the record where the second character of Name field is a and where the fourth character is t.
|

Uses of from {x}syntax:
|
|
A |
|
|
1 |
=file("score1.txt") |
|
|
2 |
=file("score2.txt") |
|
|
3 |
=A1.cursor@t() |
|
|
4 |
=A2.cursor@t() |
|
|
5 |
=[A3, A4].cursor@t() |
|
|
6 |
=connect().query("select CLASS, max(SCORE) avg_score from {A5} where SUBJECT='math' group by CLASS") |
Use from {x} syntax, where x is a cursor. |
When used in $()sql:
|
|
A |
|
|
1 |
$()select * from Persons.txt |
Query data in file Persons.txt and return result as a table sequence. |
|
2 |
$select * from D:/Orders.txt |
Query data using an absolute path and return result as a table sequence. |
|
3 |
$select * from Persons.csv where Id_P=? or Id_P>?;2,2 |
Retrieve records where Id_P is equal to or greater than 2 |
|
4 |
$select * from Persons.txt P join Orders.txt O on P.Id_P = O.Id_P |
Perform a query through a join. |
|
5 |
=arg1=create(id,num).record([1,11,2,22]) |
Set a cellset variable. |
|
6 |
$select * from arg1 |
from v syntax, where arg1is the variable across the current network. |
Uses of into syntax:
|
|
A |
|
|
1 |
=create(id,num).record([1,11,2,22]) |
|
|
2 |
$select * into Num.txt from {A1} |
Write data of table sequence A1to Num.txt:
|
|
3 |
>fname="Num_"+string(date(now())) |
|
|
4 |
$select * into {fname}.txt from {A1} |
Write data of table sequence A1 to a specified data file and generate a file whose name format is Num_yyyy-mm-dd.txt. fname is a macro, and yyyy-mm-dd is the current date.
|
