align()
Here’s how to use align() functions.
P.align(A:x,y)
Description:
Align records of a record sequence to a sequence.
Syntax:
P.align(A:x,y)
Note:
The function aligns records of record sequence P to sequence A through association between expression x and expression y.
This function is mainly used in handling primary-and-subtable joins, where expression y is usually the foreign key field of subtable P and expression x is primary table A’s primary key field. The computation compares value of expression y and that of expression x and aligns the corresponding records if they are equal.
There is generally the one-to-many correspondence between the primary table and the subtable, that is, a record in A is associated with multiple records in P.
When both parameter x and parameter y are absent, align each current record of P to the corresponding member of A.
Parameter:
|
P |
A record sequence, table sequence or pure table sequence, which is usually regarded as the subtable. |
|
A |
A sequence or record sequence to which records are aligned, which is usually the primary table. |
|
x |
A field or field expression according to which association is achieved; by default, it is interpreted as ~. |
|
y |
Alignment field or field expression in P, which is by default interpreted as ~ . |
Option:
|
@a |
Group and align all records of record sequence P according to sequence/record sequence A, and return each group of records as a member of the result sequence. By default, the function returns a sequence made up of the first member of every group. |
|
@b |
Use binary search when A is an ordered sequence. |
|
@p |
Return a sequence of sequence numbers of members in P. |
|
@n |
Return all members of P that match members of A and put non-matching members in the result set’s last group. |
|
@s |
Sort records of P according to the order of members of A and put non-matching records in the last. |
|
@v |
Return a pure table sequence when P is a pure table sequence; only supported by esProc Enterprise Edition. |
|
@o |
Perform merge-align between P and A when both are ordered. |
Return value:
Sequence/Record sequence/Pure table sequence
Example:
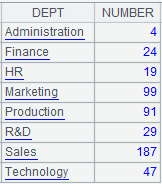
Align the subtable to the primary table and perform computations:
|
|
A |
|
|
1 |
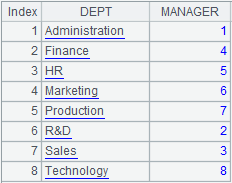
=demo.query("select * from DEPARTMENT ") |
Treat the table as the primary table.
|
|
2 |
=demo.query("select * from EMPLOYEE ") |
Treat the table as subtable where DEPT field is associated with A1.
|
|
3 |
=A2.align@a(A1:DEPT,DEPT) |
Align EMPLOYEE table to DEPARTMENT table according to DEPT field and, as @a option works, return all matching records.
|
|
4 |
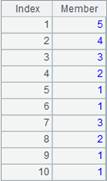
=A1.new(DEPT, A3(#).count():NUMBER) |
Perform association between A3 and A1 and list number of aligned records of the subtable EMPLOYEE in each group.
|
|
5 |
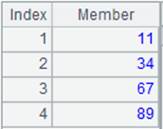
=A2.align(A1:DEPT,DEPT) |
As no option is present, only return a sequence consisting of the first member of every group:
|

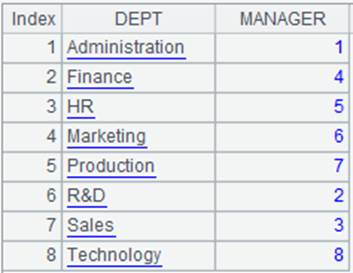
For special sorting:
|
|
A |
|
|
1 |
=demo.query("select * from score") |
|
|
2 |
=A1.sort(class) |
Sort A1 by class using sort() function and display class values in the order of four, one, three, two.
|
|
3 |
=A1.group(class) |
Group A1 by class using group() function and display class values in the order of four, one, three, two; this method cannot specify the order of groups.
|
|
4 |
=["class one","class two","class three","class four"] |
|
|
5 |
=A1.align@a(A4,class) |
Use @a option to align all members, and as parameter x is absent, display A1’s records according to the order of class field values in A4, and group the result sequence.
|

Use @b option to enable binary search:
|
|
A |
|
|
1 |
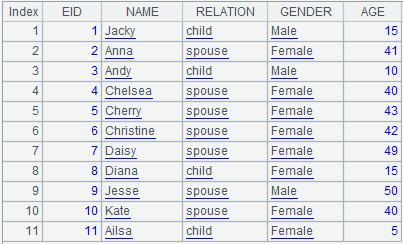
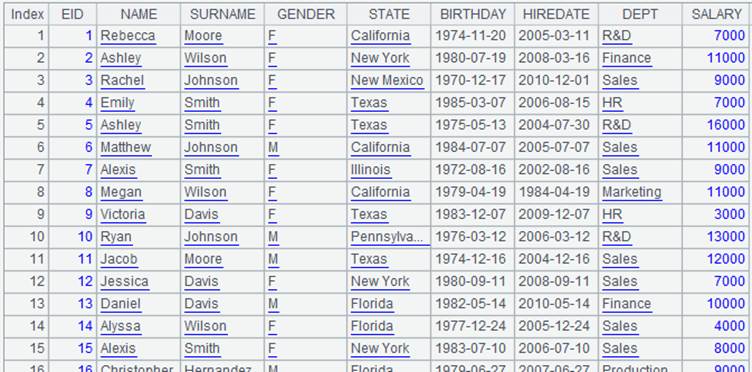
=demo.query("select * from FAMILY").sort(EID) |
|
|
2 |
=demo.query("select top 11 * from EMPLOYEE") |
|
|
3 |
=A1.align@ba(A2:EID,EID) |
As A1 is ordered by EID field, we use binary search to speed up query.
|
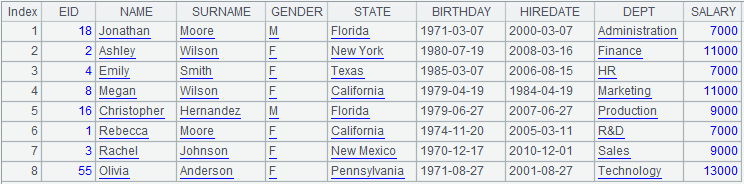

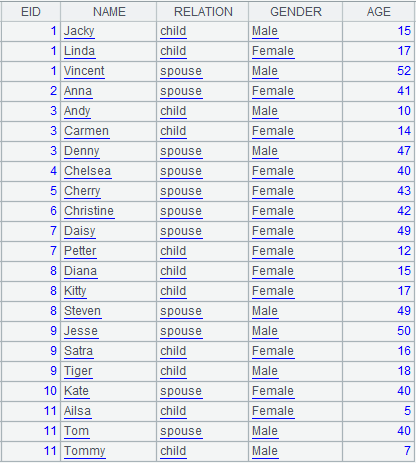
Use @p option to return an alignment result set consisting of members’ sequence numbers in P:
|
|
A |
|
|
1 |
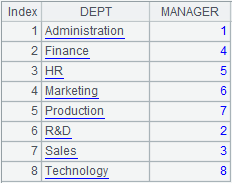
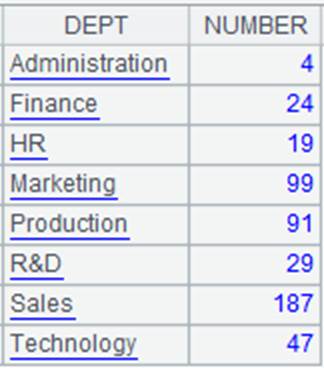
=demo.query("select * from DEPARTMENT ") |
|
|
2 |
=demo.query("select EID,NAME,DEPT,SALARY from EMPLOYEE ") |
|
|
3 |
=A2.align@ap(A1:DEPT,DEPT) |
Align A2 to A1 and return a sequence consisting of sequence numbers of members of P.
|
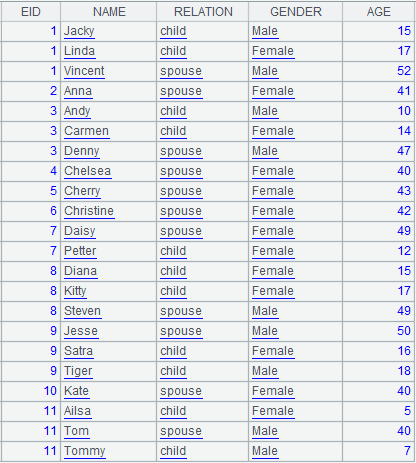
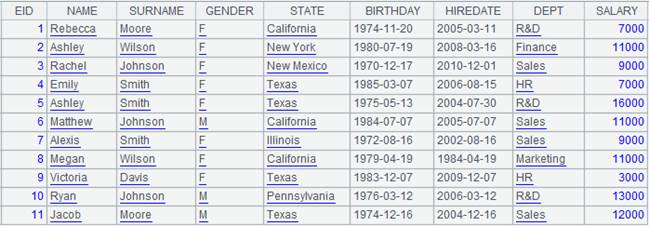
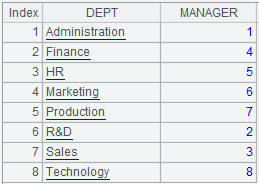
When @n option is present:
|
|
A |
|
|
1 |
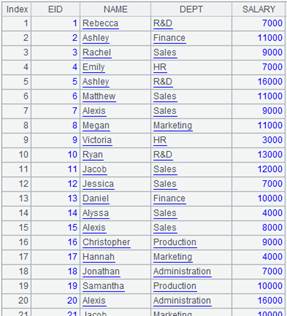
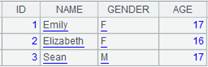
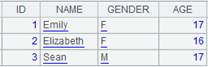
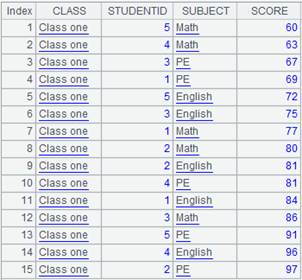
=demo.query("select top 15 * from SCORES") |
|
|
2 |
=demo.query("select top 3 * from STUDENTS") |
|
|
3 |
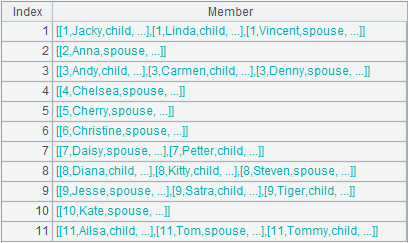
=A1.align@n(A2:ID,STUDENTID) |
The function works with @n option to align the primary table and the subtable and return all members of every group; the last group stores records that cannot match the primary table:
|
Use @s option to sort subtable records according to members of the primary table:
|
|
A |
|
|
1 |
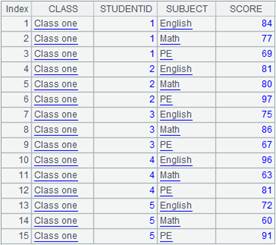
=demo.query("select top 9 * from SCORES").sort(SCORE) |
|
|
2 |
=demo.query("select top 3 * from STUDENTS") |
|
|
3 |
=A1.align@s(A2:ID,STUDENTID) |
As @s option is present, sort A1 according to A2’s ID field and put non-matching members in the end.
|

P.align(n,y)
Description:
Perform alignment grouping on a record sequence.
Syntax:
P.align(n,y)
Note:
The function divides record sequence P into n groups according to grouping expression y and alignment succeeds if the result of y equals to the corresponding group number. The function is equivalent to P.align(to(n),y).
Parameter:
|
P |
A record sequence. |
|
n |
An integer, which is the number of groups. |
|
y |
An integer or an integer sequence. |
Option:
|
@a |
Return all members for each group, where members form a sequence; the function by default returns only the first member of every group. |
|
@r |
With this option, parameter y is an integer sequence, where each member acts as an alignment position according to which a record of P is put into the corresponding one of the n groups. |
|
@p |
Return a sequence of sequence numbers of members of P. |
Return value:
Sequence
Example:
When parameter y is an integer:
|
|
A |
|
|
1 |
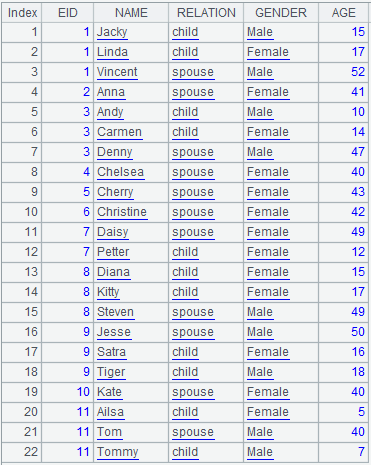
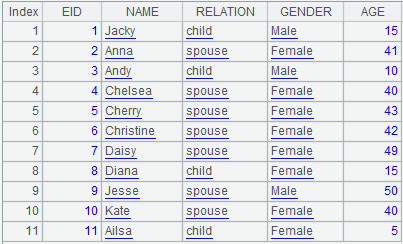
=demo.query("select * from FAMILY") |
|
|
2 |
=A1.align(11,EID) |
Divide A1’s record sequence into 11 groups according to EID values, which correspond to group numbers one by one, and return the first eligible member for each group.
|
|
3 |
=A1.align@a(11,EID) |
Divide A1’s record sequence into 11 groups according to EID values, which correspond to group numbers one by one, and, as @a is present, return all eligible members for each group.
|
|
4 |
=A1.align@ap(11,EID) |
As @p is present, return values that are sequence numbers of EID values in A1.
|

When parameter y is an integer sequence:
|
|
A |
|
|
1 |
=demo.query("select EID,NAME,DEPT from EMPLOYEE") |
|
|
2 |
=demo.query("select * from DEPARTMENT") |
|
|
3 |
=A1.derive(A2.pselect@a(DEPT==A1.DEPT): DeptNo) |
Find sequence numbers of DEPARTMENT records corresponding to EMPLOYEE table and then form them into an integer sequence and store it in DeptNo field.
|
|
4 |
=A3.align@r(8,DeptNo) |
Align records directly to group number according to DeptNo field.
|
|
5 |
=A3.align@rp(8,DeptNo) |
As @p option is present, return sequence numbers of records.
|