Export to SPLX
The data operations defined in ETL can be saved in a SPLX file in the form of the SPL script. Execute the SPL script and generate a data file according to the export settings.
On the Tool menu, there are two methods to generate a SPLX file:
1. Create SPLX File: Used to get all data from a data table and export data to a file according to export settings;
2. Create Incremental SPLX File: Used to get only the modified or new data from a data table and export the concatenation of the incremental data and the original file to a separate data file.
Create SPLX File
Click Tool -> Create SPLX File in the ETL interface and save the splx file as EmpForETL.splx. Below is the script:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
="D:\\file\\ETL\\" |
|
3 |
=A1.query("SELECT Distinct GENDER FROM EMPLOYEE") |
|
4 |
=A3.(GENDER).new(#:gender_id,~:gender).keys@i(gender) |
|
5 |
=file(A2+"EMPLOYEE_GENDER.btx").export@b(A4) |
|
6 |
=file(A2+"department.txt").import@t(DEPT,MANAGER;," ") |
|
7 |
=A6.keys@i(DEPT) |
|
8 |
=file(A2+"department.btx").export@b(A7) |
|
9 |
=A1.cursor("SELECT EID,NAME,GENDER,BIRTHDAY,DEPT,SALARY, FAMILY.EID AS FAMILY_EID,FAMILY.NAME AS FAMILY_NAME,RELATION,FAMILY.GENDER AS FAMILY_GENDER,AGE FROM EMPLOYEE LEFT JOIN FAMILY ON EMPLOYEE.EID=FAMILY.EID WHERE EID<?",arg1) |
|
10 |
=A9.sortx(EID).new(#@:id,EID,NAME,A4.pfind(GENDER):GENDER,BIRTHDAY,A7.pfind(DEPT):DEPT,SALARY, age(BIRTHDAY):EMP_AGE,FAMILY_EID,FAMILY_NAME,RELATION,FAMILY_GENDER,AGE) |
|
11 |
=file(A2+"EMPLOYEE.ctx").create@yp(#id,EID,NAME,GENDER,BIRTHDAY,DEPT,SALARY,EMP_AGE, FAMILY_EID,FAMILY_NAME,RELATION,FAMILY_GENDER,AGE).append(A10).close() |
|
12 |
=A1.close() |
Open the script file in IDE, and set value of parameter arg1 is 51 to get records where EID values are less than 51. Execute the script and you have EMPLOYEE.ctx, EMPLOYEE_DEPT.btx and gender.btx generated in D:/file/ETL.
Below is EMPLOYEE.ctx whose data is exported from source table EMPLOYEE. The composite table consists of fields resulted from joining EMPLOYEE table and FAMILY table. id column values are ordinal numbers of data rows, GENDER column values are gid values in dimension table gender, DEPT column has values of deptID in numberized table EMPLOYEE_DEPT, and EMP_AGE is a newly-added column specified in the export settings:

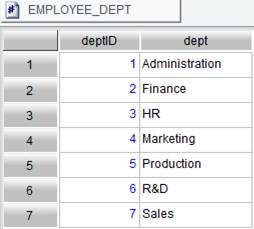
Here is the content of EMPLOYEE_DEPT.btx configured and generated through Create Enumerated Numberized Column. Its dept column contains values of EMPPLOYEE table’s DEPT field:

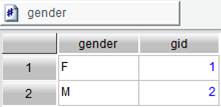
Below is content of gender.btx whose data is exported from text file source gender.txt:
Create Incremental SPLX File
In real-world business situations, data in a table is often in a state of continuous change or growth. To collect the incremental data, ETL tool provides Create Incremental SPLX File functionality, which selects target data according to the search condition, combines it with data in the source file named “source table.xxx”, and generates a new data file named “source table_New.xxx”.
Still take EMPLOYEE table as an example. In the preceding section, we selected records meeting the condition EID<51 and wrote it to data file EMPLOYEE.ctx. Suppose the number of records increases after a while and the largest EID value becomes 100, and you need to update the newly-added records to a data file without retrieving the already extracted data. To do this you can use the incremental update method according to the following directions:
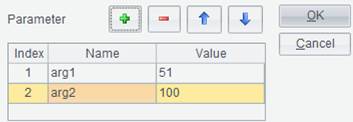
Modify T1.etl, set value of arg1 as 51, and add a parameter named arg2 and set its value as 100:
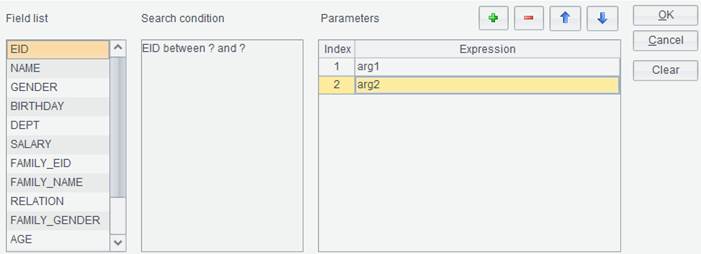
Set a search condition on EMPLOYEE table:
After these settings, click Tool -> Create Incremental SPLX File to save the incremental data in EmpForETL_New.splx:
|
|
A |
|
1 |
=connect("demo") |
|
2 |
="D:\\file\\ETL\\" |
|
3 |
=A1.query("SELECT Distinct GENDER FROM EMPLOYEE") |
|
4 |
=T1=file(A2+"EMPLOYEE_GENDER.btx").import@b().keys@i(gender) |
|
5 |
=T2=A3.(GENDER) |
|
6 |
=T3=T2.select(!T1.pfind(~)).new(#+T1.len():gender_id,~:gender) |
|
7 |
=(T1 | T3).derive().keys@i(gender) |
|
8 |
=file(A2+"EMPLOYEE_GENDER_New.btx").export@b(A7) |
|
9 |
=T1=file(A2+"department.btx").import@b().keys@i(DEPT) |
|
10 |
=file(A2+"department.txt").import@t(DEPT,MANAGER;," ") |
|
11 |
=A10.keys@i(DEPT) |
|
12 |
=T2=A11 |
|
13 |
=T3=T2.select(!T1.pfind(DEPT)) |
|
14 |
=(T1 | T3).derive().keys@i(DEPT) |
|
15 |
=file(A2+"department_New.btx").export@b(A14) |
|
16 |
=T1=file(A2+"EMPLOYEE.ctx") |
|
17 |
=T1.open().cursor().skip() |
|
18 |
=A1.cursor("SELECT EID,NAME,GENDER,BIRTHDAY,DEPT,SALARY, FAMILY.EID AS FAMILY_EID,FAMILY.NAME AS FAMILY_NAME,RELATION,FAMILY.GENDER AS FAMILY_GENDER,AGE FROM EMPLOYEE LEFT JOIN FAMILY ON EMPLOYEE.EID=FAMILY.EID WHERE EID between ? and ?",arg1,arg2) |
|
19 |
=A18.sortx(EID).new(#@+A17:id,EID,NAME,A7.pfind(GENDER):GENDER,BIRTHDAY,A14.pfind(DEPT):DEPT,SALARY, age(BIRTHDAY):EMP_AGE,FAMILY_EID,FAMILY_NAME,RELATION,FAMILY_GENDER,AGE) |
|
20 |
=movefile@y(A2+"EMPLOYEE_New.ctx") |
|
21 |
=T1.reset(file(A2+"EMPLOYEE_New.ctx");A19) |
|
22 |
=A1.close() |
Execute the above incremental script file and generate a new data file.
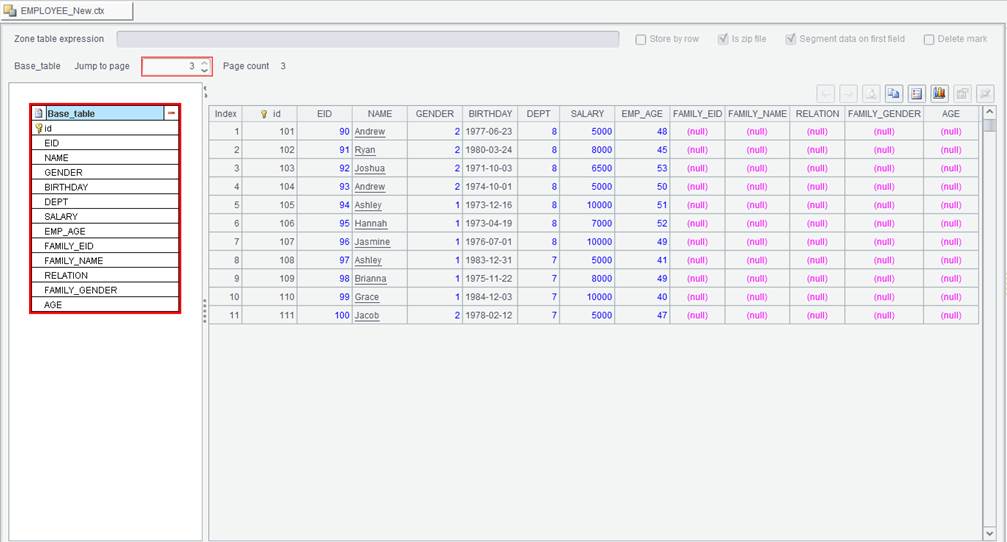
Below is the content of EMPLOYEE_New.ctx. The final result set is the concatenation of EMPLOYEE.ctx (EID<51) and the incremental data (EID>=51&&EID<=100):
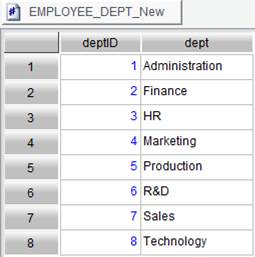
During the execution of incremental SPLX file, a new data file will also be generated from the numberized table file. In the incremental data of the EMPLOYEE table, DEPT field has a new enumerated value Technology. Correpondingly, the enumerated numberized column also gets the same incremental data. Below is content of the newly-generated EMPLOYEE_DEPT_New.btx, and the final result set is the concatenation of EMPLOYEE_DEPT.btx and the incremental data:
genter.txt remains uncahnged, so the content of gender_New.btx is the same as that of genter.txt without any changes: